





















联系我们:18818846720
邮箱地址:18818846720@163.com

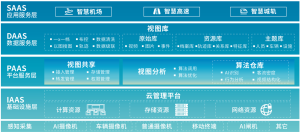
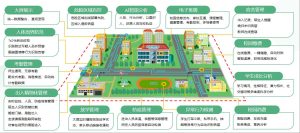
传统云计算就像把所有东西都送到中央厨房加工,而边缘计算则是把"小厨房"建在数据产生的地方。工厂设备每秒钟产生上万条振动数据,商场摄像头每天生成TB级视频,这些数据如果全部上传云端,既浪费带宽又延迟决策。边缘计算数据集的核心价值就是就地处理关键数据,只把提炼后的结果上传,比如设备异常片段或客流统计报表,让企业能实时响应问题。
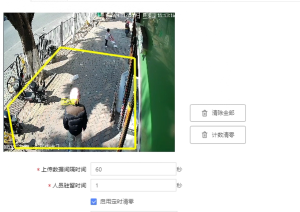
某连锁超市曾面临难题:虽然安装了AI摄像头,但网络延迟导致促销效果分析总要滞后半天。通过部署边缘计算盒子,现在能实时统计货架前停留人数,自动调整补货策略。另一个案例是风电企业,过去机组传感器数据传回云端分析要15分钟,现在边缘端10秒内就能发现叶片异常震动,维修响应速度提升90倍。这些场景的共同痛点是:海量原始数据价值密度低,但传统架构不得不为"运输垃圾"付出高昂成本。
首先在设备端部署轻量级计算单元(如英伟达Jetson),像给每个摄像头配了微型大脑;其次建立分层处理规则,比如摄像头本地识别人形轮廓,边缘服务器再汇总各区域客流热力图;最后通过Kafka等工具实现云端同步,某物流公司用这个方法把分拣线识别准确率从82%提升到97%,每年节省300万人工复检成本。记住,好的边缘数据集不是数据囤积,而是让数据在最近的位置产生最大价值。
专业工程师将为您介绍我们的产品方案


联系我们:18818846720
邮箱地址:18818846720@163.com
公司地址:广州市白云区鹤龙街康庄路4号



 微信咨询
微信咨询
 电话咨询
电话咨询
 回到顶部
回到顶部